
세계 최초로 음성·이미지·텍스트를 동시에 처리할 수 있는 자기학습(self-supervised) 인공지능(AI) 알고리즘이 나왔다. 해당 알고리즘은 자기학습으로 훈련해 데이터 레이블링이 필요 없다. 기존 단일 목적 알고리즘보다 오류율도 적다. 향후 알고리즘이 복잡한 문제를 스스로 해결할 수 있는 능력이 더 커질 전망이다.
메타플랫폼(이하 메타)이 세계 최초로 음성·이미지·문자를 동시에 처리할 수 있는 AI 자기학습 알고리즘 ‘데이터-투-백(Data2vec)’을 개발했다고 24일 밝혔다.

해당 알고리즘은 이미지·음성·텍스트에서 대상 표현을 계산하기 위해 ‘큰 네트워크(Teacher Network)’를 우선적으로 사용했다. 입력값 일부를 마스킹(masking)하고 ‘작은 네트워크(Student Network)’로 프로세스를 전달해 반복한다.
큰 네트워크는 높은 예측도를 가진 복잡한 모델을 의미한다. 작은 네트워크는 큰 네트워크 모델이 주는 지식을 받는 단순한 모델이다. 스승이 제자에게 지식을 가르치는 원리로 생각하면 된다.
여기서 작은 네트워크는 입력값 일부만 알아도 전체 값을 예측해야 한다. 작은 네트워크가 큰 네트워크만큼 입력값 전체를 쉽게 파악하도록 지속적으로 학습하는 원리다. 스승에게 배운 지식을 스스로 응용할 수 있을 만큼 반복적으로 연습하는 과정과 비슷하다.
기존 자기학습 알고리즘보다 성능 높은 이유는
데이터-투-백은 자기학습 훈련으로 음성·이미지·문자 기능을 모두 처리할 수 있다는 게 가장 큰 특징이다. 기존 알고리즘은 대부분 단일 목적에 지도기반(supervised) 학습으로만 이뤄졌다.
예를 들어, 지도학습 텍스트 알고리즘은 문장 빈칸만 채우는 훈련만 했고, 음성용은 소리에 비어있는 발음이나 단어를 예측하기만 했다. 이미지용 알고리즘은 한 그림에 대해 비슷한 색이나 모양을 가지고 그림 전체 모양을 유추하는 훈련만 했다. 모두 사람이 입력한 데이터 기반으로 처리하는 방식이다.
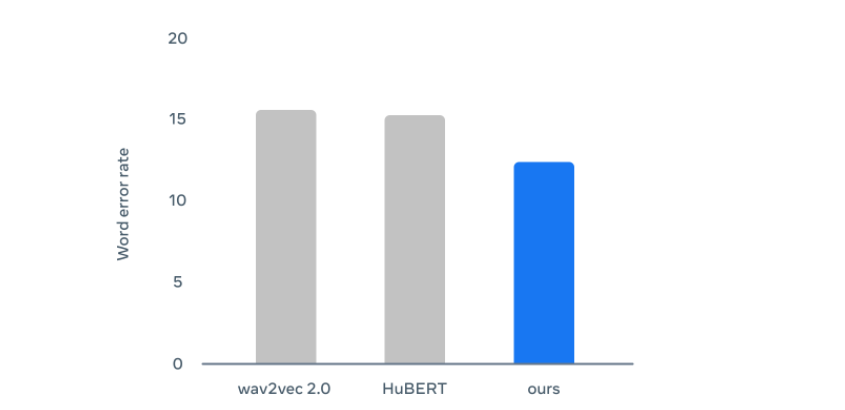
특히 음성에서는 메타가 기존에 개발한 ‘wav2vec 2.0’이나 ‘휴버트(HuBERT)' 보다 성능이 높았다. 문자 면에서는 구글 ‘버트(BERT)’ 업그레이드 버전인 ‘로버타(RoBERTa)’만큼 고성능을 자랑했다.
그동안 지도학습 기반 모델은 대부분 데이터 레이블링이 필요했다. 다시 말해, 입력된 데이터 이외의 것들은 인식할 수 없다는 말이다. 사람이 데이터를 넣어 업그레이드하지 않으면 해당 알고리즘은 발전하지 않는다. 방대한 데이터량을 수집도 연구자에게 곤혹스럽기만 하다.
데이터-투-백은 세 가지 항목을 모두 예측하기 위해 신경망층에 집중했다. 이는 단일 목적에 그치치 않고 다양한 유형에 접근할 수 있게 해준다. 다시 말해 수동적으로 데이터에만 집중해 소리나 이미지를 처리하는 게 아니라 신경망을 통해 세 가지 유형 모두 한 번에 예측할 수 있다는 말이다. 해당 방식은 데이터 레이블링이 아닌 알고리즘 스스로 유추할 수 있는 기능을 만든다.

메타 연구진은 해당 논문에서 “이제 AI는 능동적으로 완전히 낯선 작업도 스스로 해낼 수 있어야 한다”고 주장했다. 예를 들어, 이미지를 인식할 때 알고리즘 데이터에 저장된 동물이 무엇인지 알아맞히는 것뿐만 아니라, 데이터에 없는 동물이 어떻게 생겼는지 설명하면 AI가 스스로 분석하고 맞히는 수준이 필요하다는 것이다.
또 "AI가 수천 가지 언어 인식 모델을 교육하기 위해 모든 데이터를 수집하는 것은 현재 불가능하다"며 "해당 연구 성과는 인간처럼 스스로 학습하고 발전하는 ‘일반 인공지능 모델(General Model Architectures)’ 발전의 초석이다"고 연구진은 자신했다. 해당 논문에 사용한 소스코드는 깃허브에서 확인할 수 있다.